Coté
Things I Like
There are many things I like, but these are some I can think of now1:
- Above all else, I like making content and publishing it.
- I like reading short things (I used to like books, but now that I know a lot of the 101 stuff after ~40 years, I get frustrated/bored by how long it takes to get the good stuff/the point. I know the context, I want the fix.)
- I like eating; I like drinking; I like cooking.
- I like browsing markets and shops, but I’m indifferent to buying and possessing what they’re selling.
- I like all museums.
- I like to ride my bicycle.
- I like being in flow.
- I like friends telling me interesting stories, just talking to me.
- I like flâneuring, but only in dense, chaotic cities.
- I like traveling.
- I like airports and hotels.
- I like driving.
- I like whatever Anatomy of Norbiton is; A Short Life in a Strange World is one of the only books I’ve read three times; Joan Didion; Hunter Thompson; Chuck Klosterman; Susan Sontag’s diaries (she has to remind herself to take showers more - YES!); Bruce Sterling lectures (his 2024 SXSW talk relating Leatherman multi-tools to…everything?…is representative) and wastebooking; I like people who use and then build up small, boring observations to try to figure out what the is going on woth everyday life (recently, taylor.town and Noah Kalina). That is:
- I like people who are just as confused about “real life” as me and document their IRL safaris.
- I like Tex-Mex. I like Texas BBQ. I like Texas food.
- I like the idea of learning new languages.
- I like the English language as she is spoken.
- I like structured day-dreaming (e.g., solo-roleplaying D&D).
- I like complaining about bad strategy (but I wish I didn’t).
- I like coffee.
- I like money. More-so: being able to buy whatever I want, when I want, like:
- I like Apple products.
- I like music.
-
If you are thinking “but I’m not on that list, don’t you like me?” Don’t worry, I love you even if you’re not on the list. ↩︎
Open Source usage survey
Some commentary on a recent survey commissioned from my work, VMware.
Unsurprisingly, open source is used by almost everyone. When it comes to what I care about software development, open source is indispensable. In fact, it’s hard to imagine a developer who only uses closed source software, if not whole systems like kubernetes or Cloud Foundry for running their applications. It’d almost be impossible.
And, indeed, in our State of the Software Supply Chain survey this year, 2022, 90% of respondents said they were using open source in production.
Still, I wonder what those other 10% are doing!
Do they write all their own software? They’re not running Linux in production I guess, either.
What’s holding those 10% back?
- 44% selected we’re still figuring out how to manage OSS in production.
- 38% chose we don’t see sufficient support for open source software in production environments
- 34% chose we don’t trust open source software for production environments.
Benefits
There’s so much they’re missing out on. For all this praise about open source for me, what are the benefits of using open source?
80% of people said reduced costs. Now, a lot of people will tell you that open source isn’t free. What they mean is that the cost of labor to use and maintaining it (upgrading and security patching) in staff time and pay…but clearly people are benefiting from open source overall being cheap. And, of course, many companies pay for commercial support and closed source tools for the open source stuff they use.
Cost was also the number one benefit in our 2021 survey.
The other benefits were flexibility, support from a large community, and developer productivity.
All of these are the promises of open source and what we’ve come to expect over the decades. Indeed, if you look the reasons people chose open source and then the benefits they got, those expectations pretty much line up. For example, 50% of people said they expected developer productivity as a benefit, and 52% got that benefit.
Problems: Security
Let’s look at the concerns people have.
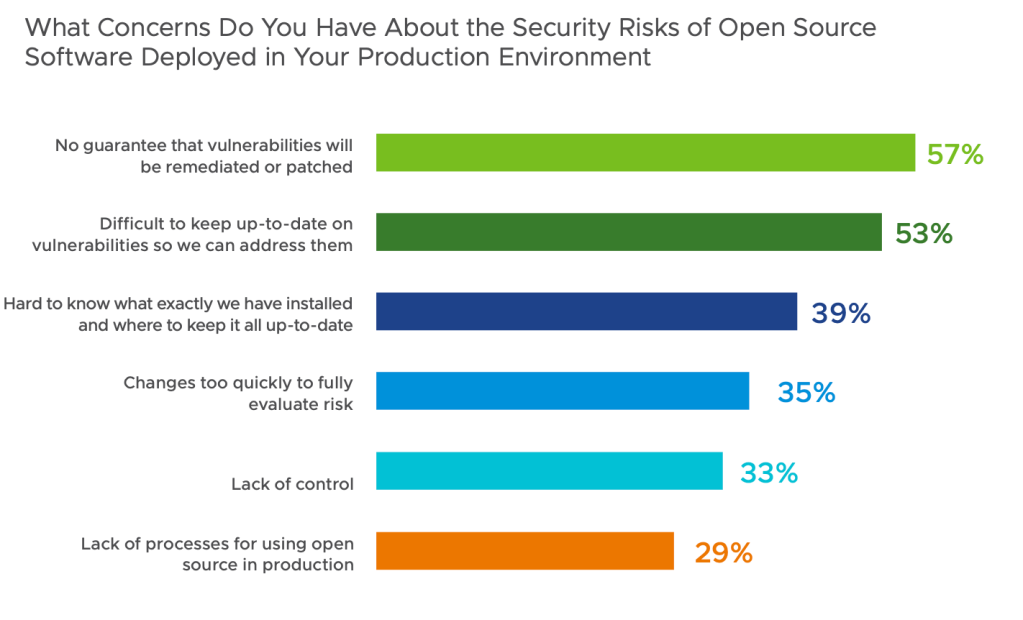
Security is what we should really dig into since it’s such a big concern. Now, I don’t think the concerns about security mean that open source is NOT secure. I don’t really think that’s the case at all. I think open source tends to be as secure as any other type of software, closed or run in the public cloud. What’s important is that you have the right process, packaging, and management in place. Again, this is important for anytime of software. Open source software is as secure, or, if you like, as insecure as closed source software. Make sure to get the right tools in place.
I want to add my own criteria for using open source that you should consider: make sure there’s a thriving, well supported community that you can depend on for the long-term. There’s two reasons for this: you want to make sure you’ll get community-based support when you’re learning how to use the OSS and troubleshoot it. Also, you want to make sure over the years that new, innovative features are added.
A thriving community will address these criteria.
Packaging and management
What you want to do is make sure that community and the vendors and cloud services you work with prioritize getting updates and patches out for their open source packages and services. And this is about more than “security”: it’s just upgrading to new versions of the projects you use to get new features and performance improvements.
You want to have the processes and tools in place to deploy those updates as soon as possible, ideally without taking down production and stopping the business from running.
The container-based applications that run in kubernetes and Cloud Foundry - both open source! - provide excellent ways to do this nowadays. For example, the US bank Wells Fargo runs many applications in containers and because of how open source is packaged and managed in their platform, they’re able to deploy updates multiple times a week without disrupting their applications and, thus, business. I’ve seen this across banks, government agency, retailers: you name it.
So what you see in our second survey, here, is that with the right tools and process in place, and managing how your open source is packaged, you can get tremendous benefits from cost savings to developer productivity. The added bonus is that these same controls for open source can be applied to your own code and software. Securing open source is important, but the more important problem to solve is securing your own software. That comes down to the same thing: tools, process, and package management.
Once you have those controls in place, you can get that innovation engine going.
How to do fun and interesting executive dinners, round tables, etc. - online and in-person
 Here’s what I’ve learned in doing 30 (maybe more like 40?) executive events in person and online over the past four or so years. Over my career, I’ve done these on and off, but it’s become a core part of my job since moving to EMEA to support Pivotal and now VMware Tanzu with executives.
Here’s what I’ve learned in doing 30 (maybe more like 40?) executive events in person and online over the past four or so years. Over my career, I’ve done these on and off, but it’s become a core part of my job since moving to EMEA to support Pivotal and now VMware Tanzu with executives.
At these events, I learn a lot about “digital transformation,” you know, how people at large organizations are changing how they build software. But, below are some notes on what I’ve learned about doing the events themselves.
The events
These usually get together a of 8 to 12 people who’re up “upper management” and involved in changing organization structure, practices, and “culture” to get their groups better at software. They’re usually very large companies: banks/insurance, manufacture/pharma, government, etc.
We used to host dinners, in person to meet these people and tell them about Pivotal, now VMware Tanzu. These dinners were eight to about twelve people. You have pre-dinner drinks and hanging out, sit at a table and eat a meal (fish, meat, or chicken - usually very good from a luxury hotel kitchen), discuss “digital transformation” during dinner, and then have drinks on the bar with about four or five of the attendees who stay.
This doesn’t work when you’re in lock-down for two years now. So, we shifted to doing these events online. I’ve been the primary anchor - the entertainment, as it were - for something most of these in Europe that are in English.
When we started, we didn’t know if they were going to work or how and had to figure it out along the way. Now, we’ve got a good formula and here are some things that work:
- First, the format, or “run of show”: fun chit-chat as people join the meeting, an introductions round, the novel event, a short presentation to establish the topic and provoke some questions, open discussion, and then a thanks and tiny vendor pitch at the end.
- Do an introductory round at the start. Each person gives their name, title/role, what they’re working on, and most important what they’re looking to get out of the event. This is good for both parties (vendor and attendee) to get to know each other, and their interests good. It also comes into play in moderating the discussion at the end. For discussion in the group, this part is really handy because it lets everyone know what people will be interested in talking about.
- Have a “novel event,” a fun activity some kind that often involves something you’ve sent the attendees. For most of these, we’ve had a sommelier do wine tasting. We ship three little bottles of wine to each attendee and the sommelier walks through each wine for about 30 or forty minutes. The one we work with is fantastic, telling the history of the wine and the region it’s from more than the mechanics of drinking. We’ve also had beer tasting, and in the States they’ve done bourbon tasting. For Christmas we did gingerbread tasting. I once ran a Nutella tasting. A nice dinner is the “event” of an in-person round-table, and you need a hook for these online ones.
- Alcohol is a good ice-breaker and the best event to have. I don’t know what to tell you: it works and people appreciate getting free wine. The wine is good, but the stories and conversation around the wine get people’s in a sort of learning/thinking mode.
- For online events, have a PowerPoint. I use that word instead of presentation because it evokes the most cringe. For in-person events, interrupting a sit-down dinner with someone going up and presenting slides is practically taboo, and certainly weird. It just makes things too commercial and introduced a formal tone that messed up the conversation. But, online, things are very different. We ended up coming up with a 10 or 15 minute presentation that basically describes what good software development looks like with a few customer examples: “product, not project” to use one framing. I found that doing this is much less about discussing exact technologies (or “vendor pitching”), and more about level-setting what we’re going to be talking about, introducing topics and problems to discuss. It’s important to have at least one story that illustrates this point. The mechanic of this presentation is to say “this is what we’re talking about, here’s a language for it, and here is one example we can refer to.” Without a shared vocabulary and some anchors, you’ll end up spending all of your discussion time on definitions. This defines “the what,” the end goal that attendees are shooting for. Most people are struggling with “the how” of getting there. So, at the end I put up a list of common hurdles and problems. This is what drives the third part:
- Moderated open discussion about people’s challenges and successes in changing their organization (transforming). I end my little presentation with a list of about ~15 common hurdles. Then I ask people to share their stories, things that have worked, that they struggle with. Sometimes getting people to start talking is like pulling teeth. I’ve had to specifically call people out before. But, often there’s at least one person who will start with a story, e.g., “you listed finance as a problem. I agree, we are struggling with getting finance onboard with shorter development cycles and being open to changing plans.” At that point, people start talking, often even giving advice to each other. I love this part!
- After the first few comments, this is where I’ve forced myself to do actual conversation moderation. I say forced because, if you know me, you’d be shocked that I would be doing this - I don’t like talking with groups. I’ve learned to figure out the people who are talkers, the ones who are reluctant to talk, and to balance out the two. This requires two things: predicting a topic that someone could comment on and abruptly changing the topic of conversation, often by calling on someone new to talk. Predicting what people can talk about is usually drawn from the introductions, or past comments they’ve made in the chat. You don’t want two or three people to dominate the conversation, which is a common risk. So you have to draw people in. To do this, you can ask them directly to follow up, or you can just change the topic of conversation all the sudden and have them kick it off: “Those were some interesting comments on dealing with finance. Now, I’m interested in how you’re dealing with legacy systems. In the introductions, it sounded like the bank Alexandra works with had a lot of legacy systems: Alexandra, how have you been dealing with that?”
- At the end, you wrap up by saying “let me tell you a little bit about what we actually do and how you can engage with us more.” If you keep this to five minutes and thank everyone for showing up, it’ll be fine and not too “don’t do a vendor-pitchy.”
- In person events are slightly different. There is no presentation. Instead I have to sort of wing it and rather than being methodical and laying it all out (a presentation!), I just talk about what it means and looks like to do software better: the practices, an example story, what new tools make all this possible, and a few common hurdles. This generally works to get people to the open discussion, which is the goal of these get togethers. I’ve gotten a little rusty at this as all the events have been online for the past two years, but after a couple so far, I’m starting to remember how to do this.
- For in person events, I think it’s handy to have about 30 minutes of hanging out before things start, and even an event or some type. Most recently, we did a Formula One simulation game. An event is always fun and relaxes people, but all of this time also allows me to meet people and find out what they’re interested in. It’s totally workable (and not weird) to ask people what they work on and what they want to get out of this event. People will just tell you - and happily! And then you can start up conversations with them that you later draw on.
- Again, the goals of all of this is for people to get to know one another and learn from each other. You can do a surprising amount of that in 90 to 120 minutes. I think this is because people are genuinely interested and engaged/learning and because my co-hosts and I have learned how to moderate and drive conversations.
- Sometimes, instead of my short presentation, we’re lucky enough that to get one or two customers to speak. These are great, I usually I ask a few questions and sometimes the customer does a short presentation. We’ve had people from Audi, Rabobank, Daimler, Tesco Bank, Cerner, and other places. When you do this, you of course need to spend time with the person up front: not so much on content (you should let them talk about whatever they want however they want), but more just get friendly with them to set the tone of the meeting. And, of course, it’s a chance to meet and learn from someone new! Having a customer talk is always preferable, but rare to be lucky enough to get.
Behind the scenes
I don’t do much or the behind the scenes work for these, and it’s a lot of work. I’ve been very fortunate to have the support, belief, and, really, my ongoing nurturing/training from my co-workers who actually run all of this. My friend Hinada Neiron has done a lot of that work and she’s done a great job putting up with me and making sure I don’t slack.
Here’s the behind the scenes stuff that happens:
- Finding and recruiting the attendees. I’m not too sure how this happens as we work with an agency that helps us. They’re great at it. Also, sales people and inside sales people also try to recruit people. I haven’t done much work here: I think I got two people to show up. The problem here is that you’re trying to meet new people, so you need to find them.
- The agency also reminds people to show up and will call them if they haven’t shown up yet (like, on the phone!). This actually works well and brings in people who wouldn’t have made it otherwise.
- We spend a lot of time on the landing page/description of the event. At first, I thought this was too much, but I’ve come to realize that it needs to be near perfect because people you’re inviting don’t know us too well or what we do, so we need to get their attention and interest.
- It’s important to make notes and plan followup right after the last person leaves. It’s then equally important to talk directly with whoever it going to follow-up with customers. The goal of these events, on the vendor side, is meeting new people to start working with, so you have to push your people to do that.
- I send a thank you to all the attendees on LinkedIn, asking to connect with them. And, we of course send a thank you email.
- Ongoing, I think it’s good to discuss with the team what’s working and not working, to come up with new things to try, and always be trying to make things slightly different. You don’t want to get stuck doing the same thing every time, otherwise you won’t find new things that work even better. Also, it just gets boring if you’re not experimenting a little here and there.
My own transformation
Overall, these events are great. As you can probably tell by some of my comments above, it’s not natural for me to talk with groups of strangers, or even individuals. I go out of my way to avoid it on my life - I love self-checkout!
So, I was very worried about that at first, but with encouragement, just doing it over and over, and also experimenting with what works and doesn’t work, I’ve gotten over it.
Most of all, I’ve made sure I enjoy these events by talking about things I’m interested in and asking people whatever questions I’m curious about. You could call this “listening,” which I suppose it is. Several years ago when I was talking about this nervousness with my wife, she reminded me that I love talking about tech stuff, and learning about it…and that’s exactly what we talk about at these events! Once I realized that these were the kinds of conversations I wished I could have all the time and people I wanted to meet, it was easier to transform myself a little bit.
Anyhow, they’re good events, and I enjoy them. Hopefully I’ll see you at one of them!
Getting more eyeballs for your boring enterprise tech videos - analysis and LIFE HACKS from four months of long and tiny b2b videos by channel and numbers
Looking at four months of numbers, here’s my theories of how to get more attention for my enterprise tech videos:
- Make short ones, each with one point - 1 minute to 10 minutes.
- Post the videos natively to Twitter, YouTube, or whatever channel - don’t rely on people clicking on YouTube.
- YouTube is, in general, the worst performer for eyeballs.
- LinkedIn is the best all around performer (but, I haven’t found detailed analytics, like seconds watched versus just auto-play).
- I haven’t done enough analysis of CTAs (“click here to go to my landing page and move further along the sales funnel to giving us CASH!") but they’re near impossible - Twitter looks good, but I don’t have enough visibility into the end-to-end funnel.
- Thus, following 5: focus on ideas you want in people’s heads (brand, thought lording, reputation, etc.) over clicks/transactions.
Analysis
I do a lot of videos for my work - selling kubernetes and appdev stacks for enterprises, along with the services/consulting that go with it (hey! VMWARE TANZUUUUUU!). Over the past two months I shifted from longer form vidoes (30-50 minutes) to tiny ones.
Sort of counter-intuitively, tiny videos take just as much work as long ones - lots and lots of editing, making subtitles, making zaney thumbnails, and all the usual uploading posting around. Sometimes tony videos take more work than just uploading longer, 45 uncut minutes.
The results are dramatic though: the shorter videos I do get a lot more views and “engagement” than the longer ones. This fits common SEO, social/influencer hustler folklore: no one likes long form content. After over 15 years of podcasting and presenting and blogging, I know that folklore isn’t, you know, universally true.
The Charts
The following tables are incomplete, it focuses on the tiny videos. See the taller table that follows for the numbers for the longer videos. (Click for the larger version of each chart.)
Table 01 shows the Dec 2020 and Jan 2021 tiny videos I did. I’ve been very time constraint of late (we have to - er, get to - home school a seven and ten year old, and also need to watch a 10 month old), so I’ve shifted to doing these small videos in the time I can find, often when I’m taking my baby daughter on a walk and she finally falls asleep:
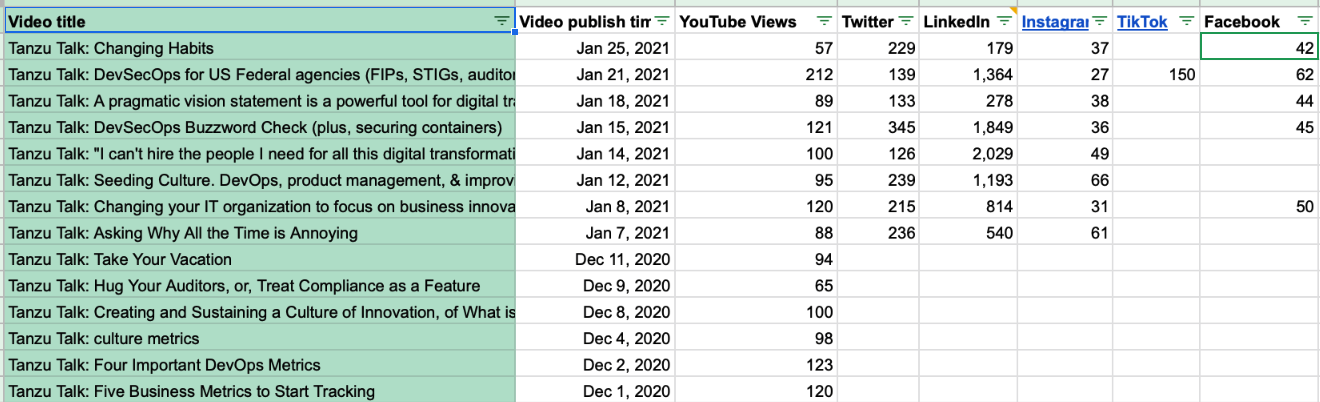{kind=link}
Table 01: Tanzu Talk tiny videos (and some long), Dec 2020 to Jan 2020.
Table 02 shows the tiny videos I did back in the Spring (2020). I was similarly time-constrained - technically (and, mostly - hey, my therapist has helped me recognize that I’m a workaholic, but, like, the content I produce for work is my passion - my work isn’t just yelling at supply chain people and arts and crafting PowerPoint slides and pivot-tables…OK…I’ll take a breath…) I was on paternity leave, so I had to snatch the times I could. I uploaded these videos to my personal YouTube site (the Dec/Jan ones are on the VMware Tanzu channel), so their YouTube views are shit:
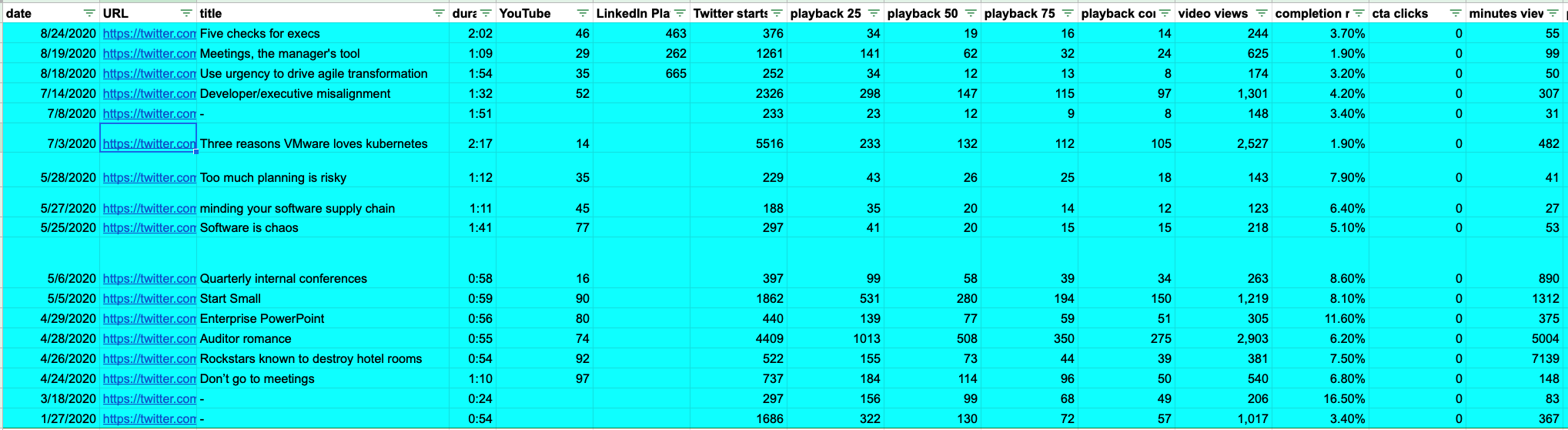
Table 02: cote.pizza tiny videos, Spring 2020.
I call these “cote.pizza” videos because that’s the URL for a CTA I had.
Then, for comparison, Table 03 the views for all the Tanzu Talk videos - most of them are long form and were only hustled with YouTube links in Twitter, LinkedIn, etc.:
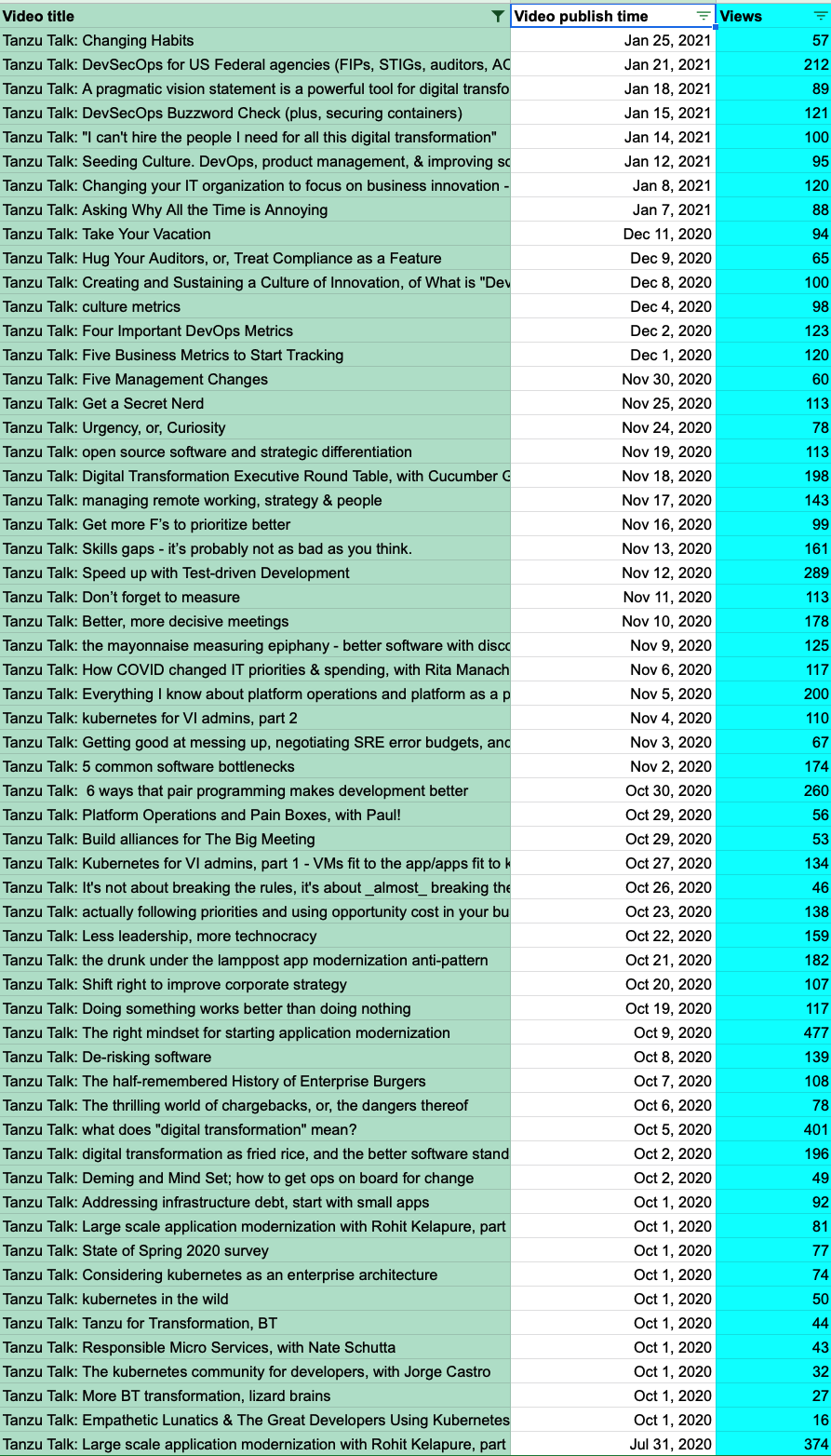
Table 03: All Tanzu Talk videos, tiny and long, 2020
Findings
There are some key findings:
- The short videos get a lot more traffic.
- Posting the videos natively to Twitter and LinkedIn gets a tremendous amount more traffic than posting links to the YouTube videos. You can see this in Table 01: the videos in December were promoted with links to YouTube, but the ones in January were posted natively to Twitter and LinkedIn. (Some videos were previews of longer ones, like the DevSecOps for Fed one).
- I haven’t done a video-by-video analysis, but very few people (if any) will click on a link to YouTube that I post in Twitter or LinkedIn. I don’t know if they click on CTAs either. (There’s some views from Instagram, Facebook, and even TikTok too, but I’m leaving those off from this write-up - they’re not high or consistent enough to consider - you’re better posting Nutella videos to those channels.)
- I have no proof of this, but I think adding in subtitles helps. Instagram will auto-generate sub-titles for you, and you can rely on YouTube’s auto-generates srt’s to upload to LinkedIn and Twitter, but I’d use something like Descript to make a “perfect” srt file.
- My Minecraft Yeller Thumbnails are the radest shit you will ever see in b2b marketing. COME AT ME. (I discovered Adobe Spark Post which is fucking awesome for this shit.)
Concerns/open questions
The major component I’m missing is following what happens when people click a CTA link. I encoded most all links I use for attribution to me, but I, of course, didn’t tell any of our web-funnel acquisition people this, so I don’t know how get those numbers. This would be extremely valuable info.
On the other hand, the price range of software and services (six to seven figure deals) I help sell is so high that having just one click, or just someone having seen and been influenced by my video evne though clicked nothing trackable.
Also, I’m concerned about echo chambers. Many of the “engagements” (likes and stuff) I get are from co-workers, which I value tremendously! There are, though, a sort of knowable set of “customers” who also engage. I need more insight into how far out of the echo chamber I’m reaching.
Let me state this clearly: I have no idea if all of this is helping the business. BUT IT SURE IS FUN TO DO!
All of that aside, let me tell you a (depressing?) secret: the only thing people care about are raw views. There may be some quibbling about completion rates, CTA following, etc.: but at the end, people will just remember the raw numbers. (Still, I’d like to have more visibility into the money I’m helping bring in and retain, but, hey, as I like to say, “I get paid either way.")
Next to try
- “Everyday someone’s born who never watched The Flintstones" - Looking at the numbers, not that many people have seen my longer form videos. Very few have watched to the end. If I slice-up and reserve some of those at tiny videos, it won’t be feed them left-overs reposting, it’ll actually be new for many people. I think this is something that us insatiable, completist readers don’t get and why we find re-posting/ICYMI’ing so vile.
- People love stuff about auditors/governance and security…but, really, you can’t predict what people like.
- Post in LinkedIn - you’ve got ten minutes, that’s a lot more than Twitter’s 2m30s.
- In Twitter, you can share access/use for the videos with other people. I need to share this with the people who run @VMwareTanzu and other accounts and see what success they get with posting those videos natively. Based on purely gut feel after looking at some of the videos, this will drive a lot more eyeballs.
Oh and… HEYYYY, GUYYZZZ! Three, two one! LIKE AND SUBSCRIBE BELOW!!
Appendix
Some additional notes as I think of them:
- Many of the longer form videos were streamed in Twitch at first. For my stuff, there’s around, I don’t know, 30 maybe 50 or 60 views after streaming in Twitch. During, it’s like zero to five, but usually, like one or two. I don’t really consider Twitch to be, uh, the “right fit” for my content. I think my co-workers who actually code (that’s like watching someone game, right?) have much more success.
5 Definitions of DevOps
I’ve tracked at least three different definitions of DevOps since the days of “agile infrastructure”:
- Using Puppet and Chef (and then Ansible and Chef) to replace Opsware and BladeLogic.
- Full stack engineers to setup EC2, load-balancers, and other Morlock shit.
- Full stack engineers are bad, but sort of the same thing. Also, you can’t have a DevOps “group” or title. But, you know, someone should do all that automation.
- Putting all the people on one team, having them focus on a product, and establishing a culture of caring and learning.
- SRE is not DevOps.
So…actually five. Maybe some of them just being footnotes on the evolving concept. (And, if you, dear reader, feel these are wrong, then let’s compromise and make the list six.)
All of them evolved around bringing down The Wall of Confusion, allowing “developers” to deploy their software to production more frequently, weekly, if not daily. And, of course, making sure production stays up. (You’re supposed to call that “resiliency” and instead of SLAs use SLOs and some other newly named metrics that answer the question “IS MY SHIT WORKING?” Whatever you do, just don’t say “uptime," or you’re in for it and will be relegated to running the AS/400’s.)
I used to snide that the developers seemed to have been yanked out of DevOps, sometime around 2014 and 2015. All the talks I saw were, basically, operations talks. I haven’t really checked in on DevOps conference talks recently, but at the time, I don’t think there was much application development stuff. (I’m not sure if there ever was?)
None of this means that DevOps is not a thing. Not at all. It just means that the enterprise finds its own use for things. It also means there’s still weekly write-ups of what DevOps is - you know, those ones that are always lists of ideas, things you’re getting wrong, and how to start.
Autonomous product teams
Nowadays, I try to stick to that fourth one: you want to set up autonomous teams that have all the skills and responsibility/authority/tools needed to “own” the software being specified, designed, developed, and run. This means you have to, basically, remove-by-automating all the operations stuff it takes to stand-up environments, deploy things, and do all that “day 2” stuff.
(HEY! HEY! WANT TO BUY SOME ENTERPRISE SOFTWARE?!)
Now, I think this product-centric notion of DevOps is, well, kind of an over-extension of the term “DevOps.” But since SRE has sucked out the “ops” part (but, remember, dear reader, don’t commit the embarrassing act of saying SRE is DevOps - no, no, you’d never do that, right? SO SHAMEFUL! (SRE is totally different - no overlap or similar goals shared between them at all. I mean, they have separate groups, silos! COME ON!)), slicing “DevOps” back to just “Dev,” but with a product-not-project focus isn’t too shabby.
Anyhow. I came across a good overview of this product notion of DevOps, all the way back from 2016, while re-reading Schwartz’s evergreen excellent The Art of Business Value:
Agile approaches attempt to bring together developers and the business in an atmosphere of mutual respect and joint contribution. Until now, however, the focus has been on users of the software, product visionaries, and developers. Recent developments in the Agile world—notably DevOps—have broadened this idea of respect and inclusion to encompass Operations and Security. The DevOps model, in other words, looks to break down the silos that have resulted from technical specialization over the last few decades. But the DevOps spirit goes further, looking to eliminate the conflicting incentives of organizational silos and the inhumane behaviors that can result from those conflicting incentives.
Perhaps we can take this idea even further still. There is no reason why the DevOps team’s responsibility needs to stop at the border of what used to be considered IT. The team is part of a broader enterprise, whose collective knowledge, skills, and judgment need to be part of the value creation process.
Look a' that guy! Business Value just effortlessly jets out of his pores like a peripatetic thought-monarch!
This is from an executives' perspective, but it drives home the point we’re always trying to get to with software: doing whatever it takes to figure out, create, and give users features that are actually useful to them. Somewhere beyond that, if you’re lucky, it’ll help out “the business.” Also, it should implement The Unspoken User Story: user would like software to actually work.
The one minute pitch at DevOpsDays
As a DevOpsDays sponsor you’re often given the chance to give a one minute pitch to the entire audience. Back stage at DevOps Rex, this week, I was talking with a first timer. One minute seems like such a small amount of time: how could you say anything consequential in 60 seconds? You’re presenting in front of the full audience, anywhere between 150 to 500 people. They probably also loath vendors, or, at least are bored by them. The stage in Paris is intimidating. It’s a huge room in an old cinema, imagine the most stereotypical movie theater from whatever “the golden age” is: double decked seats, a huge screen. Plus, the organizers are meticulous: there’s a rehearsal for these 1 minute pitches in the morning. Like a full one where you’re given a minute to talk. Normally, these pitches are very informal. Overall, it can be a public speaking challenge…plus you have to get up an hour earlier than normal.
People get rattled by these 1 minute talks and they can also give boring pitches. Here’s what how I think about them and what I do:
- The goal of this pitch is to tell people the name of your company, what you do, and to get them to come to your table to talk more.
- So, tell them the name of your company, what you do, if you have time, the story of a customer who did something remarkable, and give people a reason to come to your booth.
- People will come to your booth if you give them something: books, socks, flash lights, whatever. More senior, “decision makers” also want free stuff (they’re not monsters!), but they’ll also come to see how you can help them accomplish their work goals.
- If you can tell a joke, even a lame one (of course, not an offensive one), do it, usually towards the start of your pitch. Getting a room full of people to laugh gets them engaged and listening closer. Your pitch more memorable, and also will give you a confidence boost to coast off for the next 45 to 30 seconds.
- Finally, if you screw up, it does’t matter. It’s just 60 seconds so it’ll be over quickly and people will still come by your booth if the organizers have done their job for vendors: arranged the sponsor booth placement to drive foot traffic.
Figuring out what to say
The people like socks.
Despite how disorganized and spontaneous I may appear (that’s part of my well planned out and cultivated schtick, a safety valve for when I haven’t prepared, plus it’s a fantastically caustic feedback loop for my self-loathing — yay!) I usually prepare content before each talk.
I write a bunch of points down and reduce it to three points that I want to make. As I wait to get on the stage, I go over these three points my head; I usually write them down and look at them. Ask the local sales people what the make up of the audience is (are the developers, ops people, management, or just a general audience?), and any local events they want to drive people to.
Now, I often forget most, if not all, of that content, but that’s fine, really. Some of it will show-up. And definitely don’t let your three points constrict you, just use them as a fallback and a suggestion.
Being at a DevOps event, you should probably talk about how your company relates to DevOps. I tell people that Pivotal Cloud Foundry removes all the toil of lower-level automation that DevOps is looking to eliminate, the A in CAMS. It makes DevOps real, solves you DevOps problems, et. al., so you can get to the whole reason (the “outcome,” in business speak) for doing DevOps: creating better software and running it reliability in production.
De-wooding
The main thing you want to avoid is being stuffy. If you’re wearing a sports jacket (without being ironic), I’ve found that you’re more likely to give a stuffy talk — someone like Damon Edwards can sports-jacket all day, but he’s the exception that proves the rule.
If you’re just naturally wooden in public speaking situations, try to say something about your involvement in the pitch: how does it make you feel and how do you relate to it? Talking about yourself is easy as you’re the expert on the topic and have hopefully been there the whole time.
A little bit of humor goes a long way in these tiny talks. For example, Pivotal’s main product is well known for being more expensive than free, but it works and changes the fortunes of organizations that use it. That’s a good thing to joke about (“good thing it actually works ’cause it ain’t cheap”), or weird branding names (“for some reason, we call these ‘platform engineers’ rather than ‘SREs’”). I sometimes make a joke about PaaS, the cloud category Pivotal Cloud Foundry is in: “remember PaaS from five or so years back? It was terrible! Well, we’re a PaaS, but we doesn’t suck so much this time, it actually works!”
Don’t worry about it
The stakes of this pitch are extremely low. Look at it as more of a learning experience for yourself, practice for next time. If you biff, nothing bad will happen unless you work for shitty management that punishes you for 60 seconds of time (start looking for a new job — Pivotal is hiring!).
Some people like to memorize pitches, which is fine if that helps you. Most of all, the way to succeed at these pitches it to have fun, be playful.
You’ll be fine. Good luck!
Rule 1: Don’t go to meetings. Rule 2: See rule 1
Coffee is for coders.
Whether you’re doing waterfall, DevOps, PRINCE, SAFe, PMBOK, ITIL, or whatever process and certification-scheme you like, chances are you’re not using your time wisely. I’d estimate that most of the immediate, short-term benefit organizations get from switching to cloud native is simply because they’re now actually, truly following a process which both focuses your efforts on creating customer value (useful software that helps customers out, making them keep paying or pay you more) and managing your time wisely. This is like the first 10–20 pounds you lose on any diet: that just happens because you’re actually doing something where before you were doing nothing.
Less developer meetings, more pairing up
When it comes to time management, eliminating meetings is the easiest, biggest productivity booster you can do. Start with developers. They should be doing actual work (probably “coding”) 5–6 hours a day and go to only a handful of meetings a week. If the daily stand-up isn’t getting them all the information they need for the day, look to improve the information flow or limit it to just what’s needed.
Somewhat counter-intuitively, pairing up developers (and other staff, it turns out) will increase productivity as well. When they pair, developers are better synced up on most knowledge they need, learning how all parts of the system work with a built in tutor in their pair. Keeping up to speed like this means the developers have still less meetings to go to, those ones where they learn about the new pagination framework that Kris made. Pairing helps with more than just knowledge maintenance. While it feels like there’s a “halving” of developers by pairing them up, as one of the original pair programming studies put it: “the defect removal savings should more than offset the development cost increase.” Pairs in studies over the past 20+ years have consistently written higher quality code and written it faster than solo coders.
Coupled with the product mindset to software that involves the whole team in the process from start to end, they’ll be up to speed on the use cases and customers. And, by putting small batches in place, the amount of up-front study needed (requiring meetings) will be reduced to bite-sized chunks.
It takes a long time to digest 300 pages
We’re going to need a lot more coffee to get through this requirements meeting.
The requirements process is a notorious source of wasteful meetings. This is especially true when companies are still doing big, up-front analysis to front-end agile development teams.
For example, at a large health insurance company, the product owner at first worked with business analysts, QA managers, and operations managers to get developers synced up and working. The product owner quickly realized that most of the content in the conversations was not actually needed, or was overkill. With some corporate slickness, the product owner removed the developers from this meeting-loop, and essentially /dev/null’ed the input that wasn’t needed.
Assign this story to management
Staff can try to reduce the amount of meetings they go to (and start practices like pairing), but, to be effective, managers have the responsibility to make it happen. At Allstate, managers would put “meetings” on developers calendars that said “Don’t go to meetings.” When you read results like Allstate going from 20% productivity to 90% productivity, you can see how effective eliminating meetings, along with all their other improvements, can be on an organization.
If you feel like developers must go to a meeting, first ask how you can eliminate that need. Second, track it like any other feature in the release, accounting for the time and cost of it. Make the costs of the miserable visible.
This concept of attending less meetings isn’t just for developers,The same productivity outcomes can be achieved to QA, the product owners, operations, and everyone else. Once you’ve done this, you’ll likely find having a balanced team easier and possible. Of course, once you have everyone on a balanced team, following this principle is easier.Reducing the time your staff spends in meetings and, instead, increasing the time they spend coding, designing, and doing actual product management (like talking with end users!) get you the obvious benefits of increasing productivity by 4x-5x.
If you feel you cannot do this, at least track the time you’re losing/using on meetings. A good rule of thumb is that context switching (going from one task to another) takes about 30 minutes. So, an hour long meeting will actually take out 2 hours of an employee’s time. To get ahold of how you’re choosing to spend your time, in reality, track these as tasks somehow, perhaps even adding in stories for “the big, important meeting.” And then, when you’re project tracking make sure you actually want to spend your organization’s time this way. If you do: great, you’re getting what you want! More than likely, spending time doing anything by creating and shipping customer value isn’t something you want to keep doing.
It may seem ridiculous to suggest that paying attention to time spent in meetings is even something that needs to be uttered. In my experience, management may feel like meetings are good, helpful, and not too onerous. After all, meetings are a major tool for managers to come to learn how their businesses are performing, discuss growth and optimization options, and reach decisions. Meetings are the whiteboards and IDEs of managers. Management needs to look beyond the utility meetings give them, and realize that for most everyone else, meetings are a waste of time.
For more on improving software in your organization check out my 49 pages in a fancy PDF on the topic.
Book Review: Maximize Your Investment: 10 Key Strategies for Effective Packaged Software Implementations
The premise of this book, for most anyone, is painfully boring: planning out and project managing the installation of COTS software. This is mostly lumbering, on-premises ERP applications: those huge, multi-year installs of software that run the back office and systems of record for organizations. While this market is huge, touches almost every company, and has software that is directly or indirectly touched by almost everyone each day (anytime you buy something or interact with a company)…it’s no iPhone.
If you’re in the business of selling enterprise software and services, however, Beaubouef’s book is a rare look inside the buyer’s mind and their resulting work-streams when they’re dealing with big ol' enterprise IT. As a software marketer, I read it for exactly that. I was hoping to find some ROI models (a scourge of my research). It doesn’t really cover that at all, which is fine.
There’s a core cycle of ideas and advice flitting in and bout of the book that I like:
- COTS software will do, you know, 80% of what you like. The rest is customizing it through configuration, your own code layered on-top, or getting the vendor to add in new features.
- The more you customize the software, the harder it will be to change. But, the less you customize it, the less it creates differentiation for your business processes.
- Most of the problems and challenges you’ll encounter, though, will be human-based.
- Much of these human problems are about managing the requirements process to make sure the software is matching the needs of the business.
- Process-wise, to do this we like to take on a waterfall approach (try to specify everything up front, implement it all, then verify if it works). This results in a lot or risk of waiting for that final verification to see if it works and you were right about matching the COTS implementation to business needs.
- Instead, an iterative approach that focuses on learning and honing the COTS/business match-up seems like a good idea.
- Role-wise, getting someone(s) who has a tops-down view of the business process and enough technical understanding to map that to the COTS project is a really good idea, though hard to put in place.
While the book focuses on on-premises software, the overall thinking could easily apply to any implementation of a large IT-driven, vendor provided system: SaaS would work, and to an extent the kind of infrastructure software we sell at Pivotal. As the points above go over, the core thrust of the book is about managing how you make sure your IT is actually helping the business, not bogging down in its self.
If you’re pretty vague on what you should do in these large IT initiatives, you could do a lot worse than read this book.
Check out the book: Maximize Your Investment: 10 Key Strategies for Effective Packaged Software Implementations
Moving beyond the endless debate on bi-modal IT
I get all ants-in-pants about this whole bi-modal discussion because I feel like it’s a lot of energy spent talking about the wrong things.
This came up recently when I was asked about “MVP”, in a way that basically was saying “our stuff is dangerous [oil drilling], so ‘minimal’ sounds like it’d be less safe.” I tried to focus them on the “V” and figure out what “viable” was for their situation. The goal was to re-enforce that the point of all this mode 2/small batch/DevOps/PDCA/cloud native/OODA nonsense is to keep iterating to get to the right code.
Part of the continual consternation around bi-modal IT - sad/awesome mode - is misalignment around that “viability” and scoping on “enterprise” projects. This is just one seam-line around the splits of the discussion being unhelpful
Bi-strawperson
The awesome mode people are like:
You should divide the work into small chunks that you release to production as soon as possible - DevOps, Agile, MVP, CI/CD - POW! You have no idea what or how you should implement these features so you need to iteratively do it cf. projectcartoon.com
And the sad mode folks are like:
Yes, but we have to implement all this stuff all at once and can’t do it in small slices. Plus, mainframes and ITIL.
Despite often coming off as a sad mode apologist, I don’t even know what the sad mode people are thinking. There’s this process hugger syndrome that, well on both sides really, creates strawpeople. The goal of both methods is putting out software that makes users more productive, including having it actually work, and not overpaying for the whole thing.
The Enemy is finding any activity that doesn’t support those goals and eliminated it as much as possible. In this, there was some good scrabbling from the happy mode people laughing at ITSM think early on, but at this point, the sad people have gotten the message, have been reminded of their original goal, and are now trying to adapt. In fact, I think there’s a lot the “sad mode” people could bring to the table.
To play some lexical hopscotch, I don’t think there is a “mode 1.” I think there’s just people doing a less than awesome job and hiding behind a process-curtain. Sure, it may to be their choice and, thus, not their fault. “Shitty jobs are being done,” if you prefer the veil of passive voice.
Fix your shit
When I hear objections to fixing this situation, I try to b nice and helpful. After all, I’m usually there as part of an elaborate process to get money from these folks in exchange for helping them. When they go all Eeyore on me, I have to reframe the room’s thinking a little bit without getting too tough love-y.
“When I put these lithium batteries in this gas car, it doesn’t seem to work. So electric cars are stupid, right?
You want to walk people to asking “how do we plan out the transition from The Old Way That Worked At Some Point to The New Way That Sucks Less?” They might object with a sort of “we don’t need to change” or the even more snaggly “change is too hard” counter-point.
I’m not sure there are systems that can just be frozen in place and resist the need to change. One day, in the future, any system (even the IRS’!) will likely need to change and if you don’t already have it setup to change easily (awesome mode), you’re going to be in a world of hurt.
The fact that we discuss how hard it is to apply awesome mode to legacy IT is evidence that that moment will come sooner than you think.
(Insert, you know, “where’s my mobile app, Nowakowski?” anecdote of flat-footedness here.)
ITIL end in tears(tm)
The royal books of process, ITIL, are another frequent strawperson that frothy mouthed agents of change like to light up. Few things are more frustrating than a library of books that cost £100 each. There’s a whole lot in there, and the argument that the vendors screw it all up is certainly appetizing. Something like ITIL, though, even poorly implemented falls under the “at least it’s an ethos” category.
I’m no IT Skeptic or Charles T. Betz, but I did work at BMC once: as with “bi-modal,” and I really don’t want to go re-read my ITIL books (I only have the v2 version, can someone spare a few £100’s to read v3/4?), but I’m pretty sure you could “do DevOps” in a ITIL context. You’d just have to take out the time consuming implementation of it (service desks, silo’d orgs, etc.).
Most of ITIL could probably be done with the metaphoric (or literal!) post-it notes, retrospectives, and automated audit-log stuff that you’d see in DevOps. For certain, it might be a bunch of process gold-plating, but I’m pretty sure there’s no unmovable peas under all those layers of books that would upset any slumbering DevOps princes and princesses too bad.
Indeed, my recollection of ITIL is that it merely specifies that people should talk with each other and avoid doing dumb shit, while trying to improve and make sure they know the purpose/goals of and “service” that’s deployed. They just made a lot of flow charts and check lists to go with it. (And, yeah: vendors! #AmIrightohwaitglasshouse.)
Instead of increasing the volume, help spray away the shit
That gets us back to the people. The meatware is what’s rotting. Most people know they’re sad, and in their objections to happiness, you can find the handholds to start helping:
Yes, awesome mode people, that sounds wonderful, just wonderful. But, I have 5,000 applications here at REALLYSADMODECOGLOBAL, Inc. - I have resources to fix 50 of them this year. YOUR MOVE, CREEP!
Which is to say, awesome mode is awesome: now how do we get started in applying it at large orginizations that are several fathoms under the seas of sad?
The answer can’t be “all the applications,” because then we’ll just end up with 5,000 different awesome modes (OK, maybe more like 503?) - like, do we all use Jenkins, or CircleCI, or Travis? PCF, Docker, BlueMix, OpenShift, AWS, Heroku, that thing Bob in IT wrote in his spare time, etc.
Thus far, I haven’t seen a lot of commentary on planning out and staging the application of mode 2. Gartner, of course, has advice here. But it’d be great to see more from the awesome mode folks. There’s got to be something more helpful than just “AWESOME ALL THE THINGS!”
Thanks to Bridget for helping draw all this blood out while I was talking with her about the bi-modal pice she contributed to.
These aren''t the ROI's you''re looking for
I have a larger piece on common objections to “cloud native” that I’ve encountered over the last year. Put more positive, “how to get your digital transformation started with a agile, DevOps, and cloud native” or some such platitudinal title like that. Here’s a draft of the dread-ROI section.
The most annoying buzzkill for changing how IT operates (doing agile, DevOps, taking “the cloud native journey,” or whatever you think is the opposite of “waterfall”) is the ROI counter-measure. ROI is a tricky hurdle to jump because it’s:
- Highly situational and near impossible to properly prove at the right level — do you want to prove ROI just within the scope of the IT department, or at the entire business-level? What’s the ROI of missing out on transitioning Blockbuster to Netflix? What’s the ROI of a mobile app for a taxi company when Uber comes along? What’s the ROI for investing in a new product that may or may not work within three years, but will save the company’s bacon in five years?
- Compounded by the fact that the “value” of good software practices is impossible to predict. Drawing the causal lines between “pair programming” and “we increased market-share by 3% in Canada” can be a hard line to draw. You can back-think a bunch of things like “we reduced defects and sped up code review time by pairing,” but does that mean you made more money, or did you make more money because the price of oil got halved?
In my experience, when people are asking you about ROI, what they’re asking is “how will I know the time and money I’m going to spend on this will pay off and, thus, I won’t lose time and money? (I don’t want to look like a fool, you see, at annual review time)”
What they’re asking is “how do I know this will work better than what I’m currently doing or alternatives.” It also usually means, “hey vendor, prove to me that I should pay you.”
As I rambled through last year, I am no ROI expert. However, I’ve found two approaches that seem to be more something than nothing: (1.) creating a business case and trusting that agile methods will let you succeed, and, (2.) pure cost savings from the efficiencies of agile and “cloud native.”
A Business Case
A business case can tell you if your approach is too expensive, but not if it will pay for itself because that depends on the business being successful.
Here, you come up with a new business idea, a product, service, or tweak to an existing one of those. “We should set up little kiosks around town where people can rent DVDs for a $1 a day. People like renting DVDs. We should have a mobile app where you can reserve them because, you know, people like using mobile. We should use agile to do this mobile app and we’re going to need to run it somewhere, like ‘the cloud.’ So, hey, IT-nerds, what’s the ROI on doing agile and paying for a cloud platform on this?”
In this case, you (said “IT-nerds”) have some externally imposed revenue and profit objectives that you need to fit into. You also have some time constraints (that you’ll use to push back on bloated requirements and scope creep when they occur, hopefully). Once you have these numbers, you can start seeing if “agile” fits into it and if the cost of technology will fit your budget.
One common mis-step here is to think of “cost” as only the licensing or service fees for “going agile.” The time it takes to get the technology up and running and the chance that it will work in time are other “costs” to account for (and this is where ROI for tech stuff gets nasty: how do you put those concerns into Excel?).
To cut to the chase, you have to trust that “agile” works and that it will result in the DVD rental mobile app you need under the time constraints. There’s no spreadsheet friendly thing here that isn’t artfully dressed up qualitative thinking in quantitate costumes. At best you can point to things like the DevOps reports to show that it’s worked for other people. And for the vendor expenses, in addition to trusting that they work, you have to make sure the expenses fit within your budgets. If you’re building a $10m business, and the software and licensing fees amount to $11m, well, that dog won’t hunt. There are some simple, yet helpful numbers to run here like the TCO for on-premises vs. public cloud fees.
Of course, a major problem with ROI thinking is that it’s equally impossible to get a handle on competing ways to solve the problem, esp. the “change nothing” alternative. What’s the ROI of how IT currently operates? It’d be good to know that so you can compare it to the proposed new way.
If you’re lucky enough to know a realistic, helpful budget like this, your ROI task will be pretty easy. Then it’s just down to horse-trading with your various enterprise sales reps. Y’all have fun with that.
Efficiency
Focus on removing costs, not making money.
If you’re not up for the quagmire of business case-driven ROI, you can also discuss ROI in terms of “savings” the new approach affords. For things like virtualizing, this style of ROI is simple: we can run 10 servers on one server now, cutting our costs down by 70–80% after the VMware licensing fees.
Doing “agile,” however, isn’t like dropping in a new, faster and cheaper component into your engine. Many people I encounter in conference rooms think about software development like those scenes from 80s submarine movies. Inevitably, in a submarine movie, something breaks and the officer team has to swipe all the tea cups off the officer’s mess table and unfurl a giant schematic. Looking over the dark blue curls of a thick Eastern European cigarette, the head engineer gestures with his hand, then slams a grimy finger onto the schematics and says “vee must replace the manifold reducer in the reactor.”
Solving your digital transformation problems is not like swapping “agile” into the reactor. It’s not a component-based improvement like virtualization was. Instead, you’re looking at process change (or “culture,” as the DevOps people like to say), a “thought technology.” I think at best what you can do is try to calculate the before and after savings that the new process will bring. Usually, this is trackable in things like time spent, tickets opened, number of staff needed, etc. You’re focusing on removing costs, not making money. As my friend Ed put it when we discussed how to talk about DevOps with the finance department:
In other words, if I’m going to build a continuous integration platform, I would imagine you could build out a good scaffolding for that and call it three or four months. In the process of doing that, I should be requiring less help desk tickets get created so my overtime for my support staff should be going down. If I’m virtualizing the servers, I’ll be using less server space and hard drive space, and therefore that should compress down. I should be able to point to cost being stripped out on the back end and say this is maybe not 100% directly related to this process, but it’s at least correlated with it.
In this instance, it’s difficult to prove that you’ll achieve good ROI ahead of time, but you can at least try to predict changes informed by the savings other people have had. And, once again, you’re left to making a leap of faith that qualitative anecdotes from other people will apply to you.
For example, part of Pivotal’s marketing focuses on showing people the worth of buying a cloud platform to support an agile approach to software deliver (we call that “cloud native”). In that conversation, I cite figures like this:
- Developers at Allstateused to spend only 20% of their time coding and now it’s closer to 90%
- A federal government agency wanted to save money on call-centers by converting the workflow to a web app. They’d scheduled to complete the project in 9 months, but after converting to agile, delivered it in 6 weeks.
- When doing agile because testing is pushed down to the team level and automated, you can expect to reduce your traditional QA spend. In fact, many shops on the cloud native journey have massively eliminated their QA department as a stand-alone entity.
- ING’s savings from transforming to a more cloud-y IT setup: “Investment of €200m to further simplify, standardize and automate IT; Decommissioning 40% of application landscape; Moving 80% of applications to zero-touch private cloud.” Resulting in savings of €270m starting in 2018.
- From Orange: “Who isn’t happy to continue working when projects are delivered on average six times faster than with a waterfall approach?”
- “[R]espondents from a recent government study who have already used PaaS say they save 47% of their time, or 1 year and 8 months off a 3.5 year development cycle. For those who have not deployed PaaS, respondents believe it can shave 31% off development time frames and save 25% of their annual IT budget, a federal savings of $20.5 billion.”
- 14 months down to 6 months, 16 staff down to 8 staff: “[w]hen planning the first product developed on Pivotal Cloud Foundry, CoreLogic allocated a team of 12 engineers with four quality assurance software engineers and a management team. The goal was to deliver the product in 14 months. Instead, the project ultimately required only a product manager, one user experience designer and six engineers who delivered the desired product in just six months.”
- “We did an analysis of hundreds of projects over a multiyear period. The ones that delivered in less than a quarter succeeded about 80% of the time, while the ones that lasted more than a year failed at about the same rate. We’re simply not very good at large efforts.”
- From a 1999 study: “software projects that use iterative development deliver working software 38% sooner, complete their projects twice as fast, and satisfy over twice as many software requirements.”
- After switching over to “the new way,” one large retailer has already seen 80% Reduction in cycle time and scope and reduced cycle time from 123 days to 23 days.
- One large insurance company can now manage 1,500 apps with just two operators. There were many, many more before that. Another large bank could manage 145 apps with just 2 operators, and so on.
In most of these cases, once you switch over to the new way, you end up with extra capacity because you can now “do IT” more efficiently. Savings, then, come from what you decide to do with that excess capacity: (a.) doing more with the new capacity like adding more functionality to your existing businesses, creating new businesses, or entering new markets, or, (b.) if you don’t want to “grow,” you get rid of the expense of that excess capacity (i.e., lay-off the excess staff or otherwise get them off out of the Excel sheet for your business case).
But, to be clear, you’re back into the realm of imagining and predicting what the pay-off will be (the “business case” driven ROI from above) or simply stripping out costs. It’s a top-line vs. bottom-line discussion. And, in each case, you have to take on faith the claims about efficiencies, plus trust that you can achieve those same savings at your organizations.
With these kinds of numbers and ratios, the hope is, you can whip out a spreadsheet and make some sort of chart that justifies doing things the new way. Bonus points if you use Monte Carlo inspired ranges to illustrate the breadth of possibilities instead of stone-code line-graph certainty.
Everything is up when there’s no bottom
As an added note of snark: all of these situations assume you know the current finances for the status quo way of operating. Surely, with all that ITIL/ITSM driven, mode 1 thinking you have a strong handle on your existing ROI, right? (Pause for laughs.)
More seriously, the question of ROI for thought technologies is extremely tricky. In that conversation on this topic that I had with Ed last year, the most important piece of advice was simple: talk with the finance people more and explain to them what’s going on.
That’s the most effective (and least satisfying!) advice you get about any of this “doing things the new way” change management prattle: whether it’s auditors, DBAs, finance, PMO people, or whoever is throwing chaff in your direction: just go and talk with them. Understand what it is they need, why they’re doing their job, and bring them onto the team instead of relegating them to the role of The Annoying Others.
Check out another take on this over in my September 2016 column at The Register.